
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- hbase 저장공간 설정
- RedirectService
- fake jwt
- reids
- Armeria
- 애자일 싫타
- pinpoint
- nGinder
- OIDC
- 티스토리챌린지
- LPOS
- 7879
- jsonMarshaller
- ㅉ때
- 플루터
- save/update
- jar 배포
- 논블록킹 성능
- 핀포인트
- Loki 로그
- 노드간 통신
- 오블완
- UnsupportedOperationException
- formik
- R2DBC Paging
- pinpoint 2.5.3
- Ingress Controller Fake
- 개발 어렵당.ㅠ
- 월급루팡 일지
- intellij
- Today
- Total
대머리개발자
[solr9] 검색 품질...하악하악 본문
"불용어"라는 리스트가 인터넷이 떠돌고 있길래 그냥 가져다 적용했는데
쌉질의 화근이되었다.ㅋ
"전자현미경"라는 단어에서 전자라는 검색이 안 되서 봤더니
stopFilter에서 발라지고 있던 부분이네... 불용어(stopword) 아오!

괜히 엄한데서...그래.. 내가 바보였지..

이 정도만 추가하면 될듯 하다.
https://github.com/ageitgey/node-unfluff/blob/master/data/stopwords/stopwords-ko.txt
형태소 분석을 고정할 수 있는 설정으로 두 가지 방식이 있다.
1.stop필터
2.사용자 사전 추가
stop필터는 형태소 분석을 안 하게 하는 필터고
사용자 단어 추가는 하나의 형태로 분석을 하게 하는 필터다.
즉 결과는 같다. 하나의 단어로써 역할을 한다.
뭐 어째거나 목록을 가지고 있어야 하기 때문에.. 피곤스 하다.
"내재화"를 검색했더니... 고도+화, 자동+화, 최적+화, 정규+화, 최소+화,... ㅋ 너무 많은 단어들이 검색이 된다.
위에서 이야기 한 방식 중 하나로 처리하면 되는데 문제는 !!! 모든 단어를 추가하기가 현실적으로 녹록하지 않다.
그때그때 중간에 추가한다고 해도 애매하다. ==> 다시 색인을 해야하기 때문에
래퍼런스가 없을 때는 AI가 최고닷!
두 가지 설정을 AI가 알려주었다. 너 이새퀴 1년치 밥값 다했데이!
물론 샘플은 old한 버전이지만 눈치 코치로 설정 OK!!
1. 형태소 분석을 할 때 "한 글자"로 잘리면 byPass 설정
<filter max="255" name="length" min="2"/>2. 조사는 형태소 분석을 할 때 제외하는 설정
<tokenizer .. discardPunctuation="false" ../>
근데 이슈가 발생한다. "최소화"로 검색하지만
하이라이팅은 "최소"만 em 태그로 감싸져 있다.
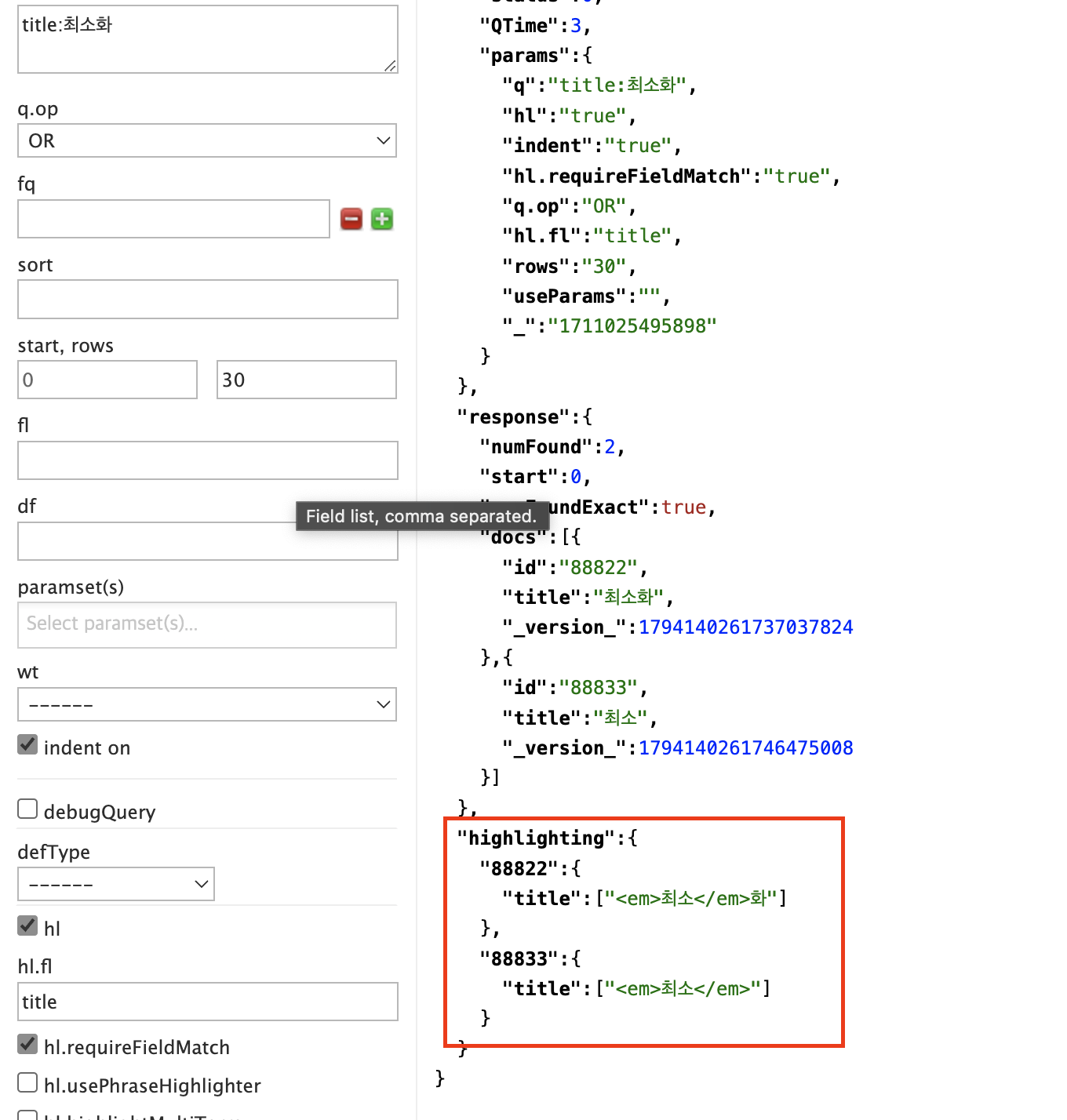
최소화에 형태소 분석되고 "최소 + 화" 분석된 단어에서 "화"를 버리고 "최소"만 인덱스 되기 때문이다...하악하악
더이상 옵션처리로는 안 되고 짱구를 굴려야 한다.!
유의미있는 검색을 위해서 한글자 분석되면 byPsss 하는 필드를 만들고
실제 검색한 단어로 하이라이팅되게 하는 방법은 역시 ai가 알려주었다.ㅠㅠ 진짜 밥값 다했어 이놈아.
핵심은 서로 다른 인덱싱이다.
// 한글자 제외 인덱싱
<field name="title" type="text_ko" indexed="true" stored="true" uninvertible="true"/>
// 전부 인덱싱
<field name="title_copy" type="text_ko_copy" indexed="true" stored="true" uninvertible="true"/>
<copyField source="title" dest="title_copy"/>
하이라이팅의 검색은 title_copy를 통해서 한다.
그럼 짜짠!!!!!!!! <em>간소</em><em>화</em>
물론 깔끔하게 처리하려면 <em>간소화</em> 맞긴 한데...언제 일일히 리스트-업을 하냐구용 ㅠㅠ
하다보면 계속 나오겠지..

검색어 품질 이제는 끝나겠지? ㅠ 피곤스 하다.
안 끝난다.ㅋㅋ
'개발이야기 > 오픈소스 설치' 카테고리의 다른 글
| 인그레스 콘트롤러 - cros 처리 (0) | 2024.06.25 |
|---|---|
| armeria framework는 누가 모니터링 해줄 꺼니.ㅠ (0) | 2024.06.24 |
| [solr9] 사용자 사전 추가 2 (1) | 2024.03.20 |
| [solr9] 사용자 사전 추가 (0) | 2024.03.20 |
| [solr9] - 미비된 사항들 정비 2 (0) | 2024.03.19 |


